
I recently encountered an issue where an index rebuild set to wait_at_low_priority ended up blocking an asynchronous statistics update.
This interaction led to a large blocking chain where queries were waiting on the async stats update and started to timeout.
How did it happen?
We'll need a basic understanding of a few concepts as well as database settings:
- 'RCSI' and 'Async stats update' database configuration
- Auto stats update and how it's triggered
- Lock partitioning
- Locking and blocking
Database configuration
- RCSI (Read Committed Snapshot Isolation) prevents reading queries from blocking writers - this helps with the concurrency
- Stats update:
- Sync stats - the query will wait for the out-of-date statistics to update before generating a plan. This might be a problem if you have a short query with a high call frequency where waiting for the stats update would take much longer than the query itself
- Async stats - when stats recomputation is needed it will start a background job that will update the stats later. The query is still using the out-of-date stats but at least it can continue
Let's create a test database with RCSI and Async stats update:
CREATE DATABASE StatsUpdateAsync
ALTER DATABASE StatsUpdateAsync SET READ_COMMITTED_SNAPSHOT ON WITH ROLLBACK IMMEDIATE
ALTER DATABASE StatsUpdateAsync
SET AUTO_UPDATE_STATISTICS_ASYNC ON
WITH ROLLBACK IMMEDIATE
Auto stats update
In one of my previous articles KEEP PLAN Demystified I've demonstrated how to monitor the stats update, what are the different thresholds etc., so if you're not familiar with these concepts, I suggest you read it first.
For our demo, we'll create a table with 500 rows which means that the threshold for auto stats update is also 500.
CREATE TABLE dbo.PermaSmall
(
n int
, CONSTRAINT PK_PermaSmall PRIMARY KEY (n)
)
;WITH
L0 AS(SELECT 1 AS c UNION ALL SELECT 1),
L1 AS(SELECT 1 AS c FROM L0 CROSS JOIN L0 AS B),
L2 AS(SELECT 1 AS c FROM L1 CROSS JOIN L1 AS B),
L3 AS(SELECT 1 AS c FROM L2 CROSS JOIN L2 AS B),
L4 AS(SELECT 1 AS c FROM L3 CROSS JOIN L3 AS B),
L5 AS(SELECT 1 AS c FROM L4 CROSS JOIN L4 AS B),
Nums AS(SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS n FROM L5)
, tally AS (SELECT TOP (500) n FROM Nums ORDER BY n)
INSERT INTO dbo.PermaSmall WITH(TABLOCKX) (n)
SELECT
n
FROM tally
Lock partitioning
This was the hardest piece of the puzzle because there is not a whole lot of documentation.
My main sources were:
- documentation for SQL 2008
- Bob Dorr's article How It Works: SQL Server Lock Partitioning
- Understand lock partitioning
- A previous email conversation I had with
 Jonathan Kehayias
.
Jonathan Kehayias
.
I'll summarize the key points:
- Lock partitioning is enabled by default if you have 16+ CPUs
- Startup Trace Flag 1228 can lower the requirement to 2 CPUs
- You can check if it's enabled by looking for the message Lock partitioning is enabled… in the Error Log. For example with this query
EXEC sp_readerrorlog 0, 1, N'lock partitioning'
- It's a scalability feature when some types of lock can be split into partitions enabling higher concurrency for some operations
- The number of partitions matches the number of schedulers
- Acquiring shared access requires only the local partition to be acquired
- Acquiring exclusive access requires all partitions to be acquired
- Partition lock acquires always start at 0 and go up to the number of schedulers. Lock releases have reversed direction
Locking and blocking
This should not be a new concept to most DBAs. The main tool to help with this is the Lock compatibility matrix (the complete one).
In this demo - the most important locks will be Sch-M (schema modification) and Sch-S (schema stability).
Schema is an overloaded term that can mean multiple things. In this case, it refers to the "definition" of an object.
- Sch-S lock is present in every query because you don't want the schema to change inflight. This lock cannot be removed (yes, not even with the
NOLOCKhint). - Sch-M lock on the other hand blocks everything and must wait on the release of all the Sch-S locks so you can for example add a new column or rebuild an index, etc.
Demo
Control the assigned scheduler
We're almost ready to start the demo, but there is one more consideration that caused me a headache. In the Lock partitioning summary, we had this bullet point:
Acquiring shared access requires only the local partition to be acquired
The local partition matches the scheduler_id that the session is running on. If we want a repeatable demo, we must be able to control the session's scheduler assignment. After some attempts with closing and opening new sessions hoping for the desired scheduler, I've opted to use the Resource Governor's AFFINITY option.
This snippet will dynamically create Resource pools with workgroups per scheduler and a Classification function that will match the workgroup to the application name.
DECLARE @schedulerCount int
SELECT
@schedulerCount = dosi.scheduler_count - 1 /* zero based */
FROM sys.dm_os_sys_info AS dosi
DECLARE
@i int = 0
, @dynamicSql nvarchar(MAX) = N''
WHILE @i <= @schedulerCount
BEGIN
SET @dynamicSql = N'
CREATE RESOURCE POOL SchedulerPool' + CAST (@i AS varchar(2)) + N'
WITH (AFFINITY SCHEDULER = (' + CAST (@i AS varchar(2)) + N'));'
EXECUTE sp_executesql @dynamicSql
SET @dynamicSql = N'
CREATE WORKLOAD GROUP SchedulerGroup' + CAST (@i AS varchar(2)) + N'
USING SchedulerPool' + CAST (@i AS varchar(2)) + ';'
EXECUTE sp_executesql @dynamicSql
SET @i = @i + 1
END
GO
CREATE OR ALTER FUNCTION dbo.ClassifierFunction()
RETURNS SYSNAME
WITH SCHEMABINDING
AS
BEGIN
DECLARE @WorkloadGroup SYSNAME
IF APP_NAME() LIKE 'SchedulerGroup%' /* example: SchedulerGroup15*/
BEGIN
SET @WorkloadGroup = APP_NAME()
END
ELSE
BEGIN
SET @WorkloadGroup = 'default'
END
RETURN @WorkloadGroup
END
GO
ALTER RESOURCE GOVERNOR WITH (CLASSIFIER_FUNCTION = dbo.ClassifierFunction)
GO
ALTER RESOURCE GOVERNOR RECONFIGURE
GO
Now if I want my SSMS session to run on scheduler 6 I'll add an Additional Connection parameter
Application Name=SchedulerGroup6;
And I can check that it worked with:
SELECT
dot.scheduler_id
, dot.session_id
FROM sys.dm_os_tasks AS dot
WHERE dot.session_id = @@spid
Plan of action
To demonstrate the blocking, I will:
- Start a reading query in a transaction with
HOLDLOCK. I will only read the last row in the table - Start an index rebuild with
WAIT_AT_LOW_PRIORITYand a long timeout so we have time to test this- This will be blocked because of the Sch-S lock from the reading query
- To demonstrate the blocking, this should be running on a scheduler with a high number (let's say 10)
- Modify the table a couple of times to bring the stats modification counter over the threshold
- This is not blocked by the reading query as I'm only reading the last row
- It's also not blocked by the index rebuild which waits in the low-priority queue
- Run a query reading from the table - this will trigger the Async update stats
- To demonstrate the blocking we can run the reading query again from a session lower than 10
Blocked rebuild
Let's run the first few steps:
Run this query in the StatsUpdateAsync database - the scheduler_id doesn't matter yet
USE StatsUpdateAsync
GO
/* Blocker */
BEGIN TRAN
SELECT
*
FROM dbo.PermaSmall AS ps WITH (HOLDLOCK)
WHERE ps.n = (SELECT 500)
-- ROLLBACK
In another session with the app name Application Name=SchedulerGroup10 run
SELECT
dot.scheduler_id
, dot.session_id
FROM sys.dm_os_tasks AS dot
WHERE dot.session_id = @@spid
USE StatsUpdateAsync
GO
/* Rebuild */
ALTER INDEX [PK_PermaSmall] ON [dbo].[PermaSmall]
REBUILD WITH
(
ONLINE=ON
(
WAIT_AT_LOW_PRIORITY
(
MAX_DURATION = 50 MINUTES /* I don't mind waiting */
, ABORT_AFTER_WAIT = SELF
)
)
)
The query will be stuck in executing and we have 50 minutes to run our test.
Now we'll run the update query twice and check the modification counter
USE StatsUpdateAsync
GO
/* Updater */
UPDATE p
SET p.n = p.n /* fake modification */
FROM dbo.PermaSmall AS p
WHERE p.n <= 250
OPTION (KEEPFIXED PLAN)
SELECT
obj.name AS tableName
, stat.name AS statName
, CAST(sp.last_updated AS time) AS Last_update_time
, sp.rows
, sp.steps
, sp.modification_counter AS modCounter
, d.compatibility_level AS CL
, 500 AS threshold
FROM
sys.objects AS obj
JOIN sys.stats AS stat
ON stat.object_id = obj.object_id
JOIN sys.stats_columns AS sc
ON sc.object_id = stat.object_id
AND sc.stats_id = stat.stats_id
AND sc.stats_column_id = 1
JOIN sys.columns AS c
ON c.object_id = obj.object_id
AND c.column_id = sc.column_id
CROSS APPLY sys.dm_db_stats_properties (stat.object_id, stat.stats_id) AS sp
JOIN sys.databases AS d
ON d.database_id = DB_ID()
WHERE
obj.is_ms_shipped = 0
AND obj.name LIKE N'Perma%'
ORDER BY sp.rows
OPTION (RECOMPILE, KEEPFIXED PLAN)

Now by running a reading query once we trigger the async auto stats update.
Let's take a look at the locks:
SELECT
dtl.request_session_id AS spid
, CASE
WHEN deib.event_info IS NOT NULL
THEN LEFT(deib.event_info, 20)
WHEN debjq.object_id1 IS NOT NULL
THEN 'Async stats update'
ELSE
'N/A'
END AS Spid_Info
, dtl.resource_lock_partition AS lock_partition
, dot.scheduler_id
, dtl.resource_type AS type
, dtl.resource_subtype AS subtype
, dtl.request_mode AS lock
, dtl.request_status AS status
, dtl.resource_description
, dtl.resource_associated_entity_id
, dtl.request_lifetime
, dtl.request_owner_type
, dtl.lock_owner_address
, debjq.session_id
FROM sys.dm_tran_locks AS dtl
JOIN sys.dm_os_tasks AS dot
ON dtl.request_session_id = dot.session_id
LEFT JOIN sys.dm_exec_background_job_queue AS debjq
ON debjq.session_id = dtl.request_session_id
OUTER APPLY sys.dm_exec_input_buffer(dtl.request_session_id, 0) AS deib
WHERE
dtl.resource_database_id = DB_ID('StatsUpdateAsync')
AND dtl.request_mode LIKE 'Sch-%'
AND dtl.resource_type = 'METADATA'
AND dtl.resource_subtype = 'STATS'
ORDER BY dtl.request_session_id, dtl.resource_lock_partition
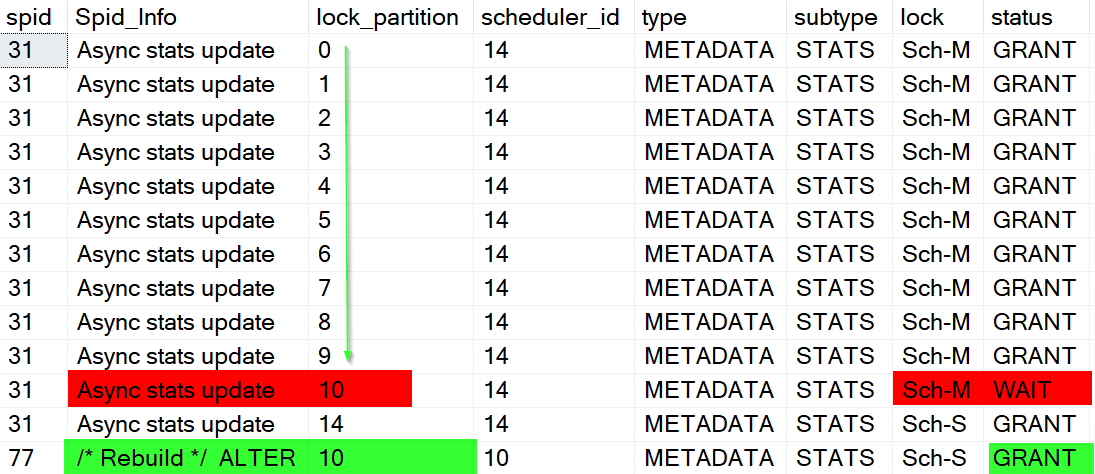
- The Rebuild task is running on scheduler 10 and is holding
Sch-Slock only on the local partition (same as the scheduler_id) - The Async stats update acquired
Sch-Mlocks on partitions 0 - 9 but because modify has to lock all partitions, it's blocked by the incompatibleSch-Sheld by the Rebuild - Now any query running on scheduler_id less than 10 will be blocked by the most restrictive
Sch-Mlock of the async stats update- But any query running on scheduler_id greater than 10 can still continue as usual
- You can test yourself by repeating the Reader or Updater query on any of the schedulers using the appropriate app_name
Solutions
Microsoft is aware of this problem and it has been fixed in the SQL 2022 (and the Azure offerings) as highlighted in this blog post Improving concurrency of asynchronous statistics update
You can enable this database-scoped configuration (it's not enabled by default)
ALTER DATABASE SCOPED CONFIGURATION
SET ASYNC_STATS_UPDATE_WAIT_AT_LOW_PRIORITY = ON
Then the lock information looks like this

This is not blocking anymore so queries can continue as usual.
As for those not on SQL 2022 yet - our solution was to update stats manually just before the planned index rebuild to minimize the chance of this happening.
It also helps if you don't have long-running queries that can block the index rebuild and auto stats update.
Thank you for reading