
Foreword
I'm still surprised many people don't realise how lousy Scalar functions (aka UDFs) are. It's my current focus at work, and this DBA Stack Exchange question nudged me too, so I'll be revisiting this topic.
The focus of part one is parallelism. Unfortunately, parallelism often gets a bad rep because of the prominent wait stats. Also, if there is a skew, it can run slow. But for the most part, it's advantageous.
Whether or not you want parallelism should be an informed choice. But Scalar functions will force the query to run serially, even if you are unaware. That's why I want to shine a light on this.
Demo
I'll be using the latest (as of the time of writing) version: Microsoft SQL Server 2022 (CTP2.0).
And I'll run it in a Docker container because I'll be changing instance settings, and I don't like to affect my other tests or clean up.
I have two reasons for using the latest version.
First, you'll see that the problem is not solved yet.
Second, SQL 2022 shows why the query didn't go parallel (you can read about that in  Erik Darling (Darling Data)
wrote about non-parallel plan reasons in SQL Server 2022).
Erik Darling (Darling Data)
wrote about non-parallel plan reasons in SQL Server 2022).
Setting up environment
Here's the Docker container if you want to follow along.
docker run `
-e "ACCEPT_EULA=Y" `
-e "SA_PASSWORD=Password1" `
-p 14335:1433 `
--name scalarfunction `
-d `
mcr.microsoft.com/mssql/server:2022-latest
First, I'll set the instance setting Cost threshold for parallelism to a low number, so our query can run in parallel.
EXEC sp_configure 'show advanced options', 1
RECONFIGURE
EXEC sp_configure 'cost threshold for parallelism', 1
RECONFIGURE
Then we can create a database. But first, I'll set the MAXDOP to 4 and disable the Scalar UDF Inlining.
This is a feature starting with SQL 2019 (Compatibility level 150), and it would interfere with the testing. I'll cover it in a future post in the series.
CREATE DATABASE ScalarFunction
GO
USE ScalarFunction
ALTER DATABASE SCOPED CONFIGURATION
SET MAXDOP = 4
/* disable inlining */
ALTER DATABASE SCOPED CONFIGURATION SET TSQL_SCALAR_UDF_INLINING = OFF
I'll also create a medium-sized table to have a query that consistently runs in parallel.
DROP TABLE IF EXISTS dbo.Nums
CREATE TABLE dbo.Nums
(
Id int NOT NULL CONSTRAINT PK_Nums PRIMARY KEY CLUSTERED
, Filler char(200) NOT NULL
)
; -- Previous statement must be properly terminated
WITH
L0 AS(SELECT 1 AS c UNION ALL SELECT 1)
, L1 AS(SELECT 1 AS c FROM L0 CROSS JOIN L0 AS B)
, L2 AS(SELECT 1 AS c FROM L1 CROSS JOIN L1 AS B)
, L3 AS(SELECT 1 AS c FROM L2 CROSS JOIN L2 AS B)
, L4 AS(SELECT 1 AS c FROM L3 CROSS JOIN L3 AS B)
, L5 AS(SELECT 1 AS c FROM L4 CROSS JOIN L4 AS B)
, Nums AS(SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS n FROM L5)
, tally AS (SELECT TOP (5*POWER(10,5)) n FROM Nums ORDER BY n)
INSERT INTO dbo.Nums WITH (TABLOCKX)
(Id, Filler)
SELECT
n
, CAST(n AS char(200))
FROM tally
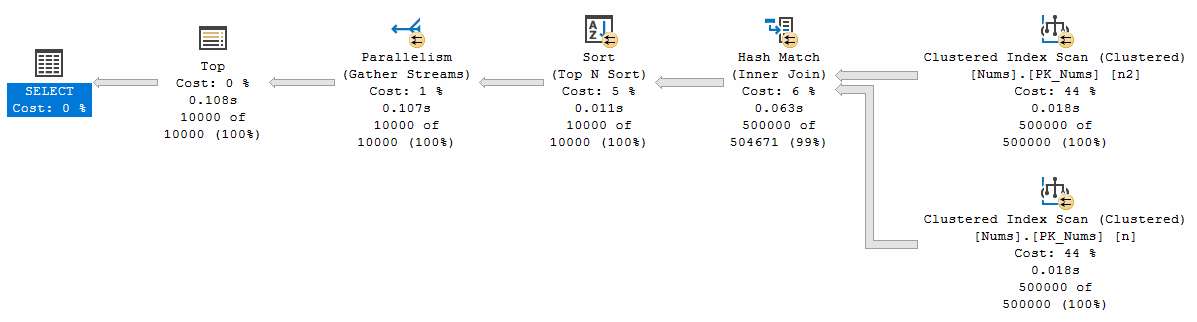
And the hero of the show: the parallel query that I'll use throughout the demos.
SELECT TOP (10000)
n.Id
, n.Filler
FROM dbo.Nums AS n
JOIN dbo.Nums AS n2
ON n.Filler = n2.Filler
ORDER BY n.Id
Getting a nice parallel plan (notice the parallelism icon ![]() on the operator nodes)
on the operator nodes)
Enter the Scalar function
I'll introduce several scenarios with a Scalar function that does absolutely nothing.
CREATE OR ALTER FUNCTION dbo.DoNothing(@Id int)
RETURNS int
AS
BEGIN
RETURN @Id
END
In a SELECT clause
Let's grab an Actual Execution plan for this query.
SELECT TOP (10000)
n.Id
, n.Filler
, dbo.DoNothing(n.Id) AS ScalarId
FROM dbo.Nums AS n
JOIN dbo.Nums AS n2
ON n.Filler = n2.Filler
ORDER BY n.Id
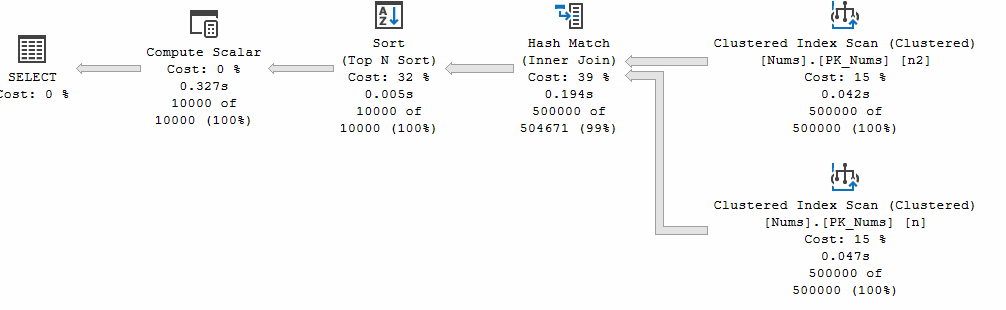
This time no parallelism icon ![]() on any of the operators, no
on any of the operators, no Gather Streams and an extra Compute Scalar just before the SELECT.
If there was any doubt that the Scalar function caused this, the properties of the main node show the reason.
![]()
NonParallelPlanReason = TSQLUserDefinedFunctionsNotParallelizable
But that's not all!
I won't be posting the execution plan and non-parallel plan reason for the following demos because it's always the same.
But I will be showcasing some scenarios which might be surprising.
In a computed column
CREATE TABLE dbo.ComputedColumn
(
Id int PRIMARY KEY
, ScalarColumn AS dbo.DoNothing(Id)
)
INSERT INTO dbo.ComputedColumn (Id)
VALUES (1)
SELECT TOP (10000)
n.Id
, n.Filler
FROM dbo.Nums AS n
JOIN dbo.Nums AS n2
ON n.Filler = n2.Filler
LEFT JOIN dbo.ComputedColumn AS cc
ON 1 = 2
ORDER BY n.Id
That's right. The Scalar function is referenced in a computed column of a table.
Also, none of the table's columns is in the SELECT clause, and it's not even usable since I'm joining on an always false predicate 1 = 2.
A Scalar function is so toxic that even a mere shadow of a reference prevents parallelism.
If you're not convinced yet, let's do another one!
In a column constraint
CREATE TABLE dbo.CheckConstraint
(
Id int PRIMARY KEY CHECK (dbo.DoNothing(Id) < 10)
)
INSERT INTO dbo.CheckConstraint (Id)
VALUES (1), (2), (3)
SELECT TOP (10000)
n.Id
, n.Filler
FROM dbo.Nums AS n
JOIN dbo.Nums AS n2
ON n.Filler = n2.Filler
LEFT JOIN dbo.CheckConstraint AS cc
ON 1 = 2
ORDER BY n.Id
Check constraint can only reference the rows that are being inserted/updated. I usually see Scalar functions in a constraint as a misguided way to introduce a complex validation that can look at other tables and rows.
Think about the implications! Any query that references this table will have to run serially.
In a View
CREATE OR ALTER VIEW dbo.ViewNums
AS
SELECT
n.Id
, n.Filler
, dbo.DoNothing(n.Id) AS ScalarId
FROM dbo.Nums AS n
GO
SELECT TOP (10000)
n.Id
, n.Filler
FROM dbo.Nums AS n
JOIN dbo.Nums AS n2
ON n.Filler = n2.Filler
LEFT JOIN dbo.ViewNums AS vn
ON 1 = 2
ORDER BY n.Id
It gives a new meaning to the "View to kill".
In a table Trigger
CREATE TABLE dbo.NumsTriggered
(
Id int PRIMARY KEY
, Filler char(100) NOT NULL
)
GO
CREATE OR ALTER TRIGGER NumsTriggered_Check
ON dbo.NumsTriggered
AFTER INSERT
AS
BEGIN
IF EXISTS
(
SELECT i.Id
FROM Inserted AS i
EXCEPT
SELECT dbo.DoNothing(i.Id)
FROM Inserted AS i
)
RETURN
END
Because this is a data modification, I'll run this test in a transaction that I'll roll back.
BEGIN TRAN
; -- Previous statement must be properly terminated
WITH RowsToInsert
AS
(
SELECT TOP (10000)
n.Id
, n.Filler
FROM dbo.Nums AS n
JOIN dbo.Nums AS n2
ON n.Filler = n2.Filler
ORDER BY n.Id
)
INSERT INTO dbo.NumsTriggered WITH (TABLOCKX)
(Id, Filler)
SELECT
Id
, Filler
FROM RowsToInsert
ROLLBACK
Ok, I'll admit this one was a red herring because the Trigger itself doesn't prevent a parallel insert.

But the statement inside the Trigger still has the same non-parallel plan reason.
Recap
- Scalar functions are evil
- They prevent parallelism when used in a query
- Even when they're not directly referenced
- View definition
- Table definition that has the Scalar function
- In a computed column
- In a check constraint
- Even if the view or table join condition won't evaluate to true.
I will cover the performance in the next part of the series.
Thank you for reading