
Twenty stolen cars, twenty swapped plates. The obvious move - join on VIN - is exactly what the thieves counted on us trying. The cars' last known locations before the swap tell a different story.
The problem
This is the abridged case description. Emphasis mine:
There has been a sudden increase in unsolved cases of stolen cars all across our city, and the police need our help again to crack the case.
We've been given access to a massive dataset of car traffic for over a week, as well as a set of cars that have been stolen. It's possible that the car's identification plates were replaced during the robbery, which makes this case even more challenging.
We need you to put on your detective hat and analyze the data to find any patterns or clues that could lead us to the location of these stolen cars. It is very likely that all the stolen cars are being stored in the same location.
And the main question:
Where are the stolen cars being kept?
More specifically: Avenue and Street numbers.
The investigation
We have two tables - StolenCars and CarsTraffic. StolenCars is just a list of 20 VINs, so let's take a look at CarsTraffic.
CarsTraffic
| take 50

The traffic data covers June 10-16, 2023 - just under a week.
So it looks to be VINs and their respective location at a point in time. My first instinct was to join directly on VIN - but swapped plates mean the stolen car shows up under a completely different VIN after the robbery. The VIN is useless as a stable link across the swap. The location is not.
If a stolen car had its plates changed at location X, then the car that drove away from X shortly afterward is the same vehicle under a new identity. The key insight: find where each stolen VIN was last seen, then find what new VIN appeared at that exact spot within a narrow time window.
The solution
- Find the last location (
AveandStreet) and time of each stolen VIN - Find new possible VINs - join on the last location within a certain timeframe - let's say 10 minutes
- Find last location of the new possible VINs
- Aggregate by location and see if any of them has around 20 cars
let LastLocation =
(
CarsTraffic
| where Timestamp >= datetime(2023-06-10) and Timestamp < datetime(2023-06-17)
| lookup kind = inner StolenCars on VIN
| summarize arg_max(Timestamp, *) by VIN
| project-rename
VinChangeTime = Timestamp
| distinct Ave, Street, VinChangeTime
);
let NewPossibleVINs =
(
CarsTraffic
| where Timestamp >= datetime(2023-06-10) and Timestamp < datetime(2023-06-17)
| lookup kind=inner LastLocation on Ave, Street
// VIN change within 10 minutes
| where Timestamp >= VinChangeTime and Timestamp < VinChangeTime + 10m
| distinct VIN
);
NewPossibleVINs
| join kind = inner (CarsTraffic | where Timestamp >= datetime(2023-06-10) and Timestamp < datetime(2023-06-17)) on VIN
| summarize arg_max(Timestamp, *) by VIN
| summarize count() by Ave, Street
| where count_ >= 20
| top 5 by count_ desc
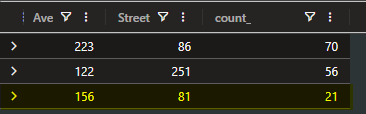
Only three locations came back with 20+ cars, so top 5 returned all three. The one with 21 is the answer: the case said all stolen cars are likely in one place, and 21 matches 20 stolen cars almost exactly. The other two clusters - 70 and 56 cars - are just busy intersections. Way too many to be a stash.
Let's input it as an answer and grab another batch.
Thank you for reading